java考试
下列关于Tomcat各服务的描述,错误的是?
Tomcat中只有一个Server,一个Server可以有多个Service,一个Service可以有多个Connector和一个Container
Service对外提供服务
Connector用于接受请求并将请求封装成Request和Response来具体处理
Service用于封装和管理Servlet,以及具体处理request请求
在Tomcat的catalina.properties中配置tomcat.util.scan.StandardJarScanFilter.jarsToSkip的作用是什么?
禁止扫描指定JAR中的Servlet注解
限制JVM加载的JAR数量
设置类加载器的双亲委派规则
启用JSP预编译功能
在 web.xml 中如何正确配置默认首页,以便访问 `/` 时跳转到 index.html?代码片段(部分缺失,请选择正确补充的代码)```xml<web-app> <welcome-file-list> ??? </welcome-file-list></web-app>```
`<welcome-file>index.jsp</welcome-file>`
`<welcome-file>index.html</welcome-file>`
`<welcome-file-list><welcome-file>/index.html</welcome-file></welcome-file-list>`
`<welcome-file>default.html</welcome-file>`
在Apache Tomcat中,以下Tomcat的Common类加载器默认加载类库是?
`$CATALINA_HOME/lib`
`WEB-INF/lib`
`$CATALINA_BASE/shared`
JRE的ext目录
在一个分布式系统中,如何正确处理Credis事务的重试机制?
无限重试直到成功
固定次数重试后报错
使用递增退避的重试策略
放弃重试直接返回错误
假设有一个集合 myset 包含元素 {x, y, z}。请问执行命令 `SREM myset y` 后,myset 中剩余的元素有哪些?
{x}
{y}
{z}
{x, z}
某系统使用 Credis 实现消息推送,已将多个客户端订阅同一个频道。现出现以下现象:- 发布消息后,部分客户端未收到任何内容- 重启客户端后可正常接收- 未收到消息的客户端应用的部分服务接口偶尔延迟会比较大同时会占用大量系统资源以下分析与解决方案中,最合理的是?
Redis 的 Pub/Sub 是推送模型,客户端订阅后必须保持连接不断,否则会错过消息,应在 Credis 客户端实现断线重连与重新订阅机制
Pub/Sub 默认启用消息持久化,客户端断线后可重连并拉取历史消息
Pub/Sub 使用的是广播模型,建议改用 List + BRPOP 保证每个客户端都能获取所有消息
Redis 会缓存所有频道消息,需配置客户端拉取速率避免堆积
某模块使用 Credis 操作数据时,需要对以下操作保证原子性:- 判断某 key 是否存在- 若不存在则写入默认值- 同时设置该 key 的过期时间以下关于使用事务执行上述逻辑的描述中,最合理的是?
通过 MULTI 包裹 GET、SET 和 EXPIRE 操作,使用 EXEC 一次性提交,Credis 客户端确保指令顺序
使用 Lua 脚本将逻辑封装为单条命令,避免 MULTI/EXEC 结构带来的性能损耗
通过 SETNX 写入并立即执行 EXPIRE,两条命令执行间仍具备原子性
使用 WATCH 监听 key,执行 MULTI 后若 key 被修改,EXEC 会自动回滚
某系统使用 Credis 实现模块间消息通知,要求满足以下需求:- 发布方将事件消息发送到指定频道- 多个订阅方可实时接收消息并独立处理- 消息不需要持久化,主要关注实时性- 订阅方能在运行时随时订阅或退订频道以下方案中最符合要求的是?
使用 Redis 的 Pub/Sub 机制,Credis 客户端通过 publish 发送消息,订阅方通过 subscribe 动态监听频道
使用 Redis 的 List 结构,发布方通过 LPUSH 插入消息,订阅方使用 LPOP 拉取
使用 Redis 的 Stream 类型,发布方添加记录,订阅方使用消费者组读取
使用 Redis 的 Set 类型保存消息内容,订阅方定时扫描并比对是否存在新消息
一个向量第一个元素的存储地址是100,每个元素的长度为2,则第5个元素的地址是?
110
108
100
120
以下关于链表的说法中,不正确的是?
链表中的元素只能按照顺序访问,不能随机访问
链表在插入和删除操作时,时间复杂度一定是O(n)
单链表中的节点至少包含两个域:数据域和指针域
双向链表相比于单向链表,空间复杂度更高
双向循环链表每个结点______。
要连接前一个节点
不需要连接节点
要连接前一个结点和后一个结点
要连接后一个节点
单链表中存在n个节点,时间复杂度为O(n)的操作是?
删除地址为 P 的节点的后继节点
删除开始节点
在地址为 P 的节点之后插入一个节点
遍历链表或求链表的第 i 个节点
带头节点的双循环链表L为空的条件是?
`L==NULL`
`L->next->prior==NULL`
`L->prior==NULL`
`L->prior==L&&L->next==L`
设有一组记录的关键字为{19,14, 23,1,,68,20,84,27, 55,11,10,79},用链地址法构造Hash表,Hash 函数为H(key)=key Mod 13,散列地址为1的链中有______个关键字。
1
2
3
4
将10个元素散列到100000个单元的Hash表中,则______产生冲突。
一定会
一定不会
可能会
不能确定
数据结构中,下列关于存储空间的说法,正确的是?
顺序存储的逻辑顺序与物理顺序可能不一致
链式存储中,元素的插入和删除操作需要移动其他节点
动态存储可以动态分配内存,提高程序的灵活性
静态存储可以在程序运行时追加内存
下列关于循环链表的说法错误的是?
每个节点都有一个后继节点
在链表头插入一个新节点的时间复杂度是 O(1)
删除最后一个节点的时间复杂度是 O(n)
可以遍历整个循环链接从任何一点开始列出
在单向链表中删除节点的最佳情况时间复杂度是多少?
O(n)
O(n^2^)
O(nlogn)
O(1)
在哈希表中什么是负载系数?
平均数组大小
平均密钥大小
平均链长度
平均哈希表长度
以下哪种技术在发生冲突时将数据存储在单独的实体中?
开放寻址
使用双向链表链接
线性探测
双散列
二次探查属于下列哪个解决冲突的方案?
重新散列
扩展散列
单独链接
开放寻址
在直接寻址中使用动态集合有什么好处?
节省时间
节省空间
节省时间和空间
降低代码复杂度
有 10 个顶点的二部图中的最大边数是多少?
24
21
25
16
对于`git merge`,以下哪个说法是正确的?
可以一次性合并多个分支
进行合并的时候会产生一个`MERGE_HEAD`的引用指向当前分支
冲突标记`<<<===>>>`中`===`上方的内容是其他分支的
合并一个`annotated tag`,当这个合并可以`fast-forward`时,Git 通常还是会产生一个合并提交
对于智能HTTP协议,以下说法错误的是?
创建版本库,只能在服务器上进行,不能通过远程客户端进行
可为Git仓库提供读写服务以及对分支进行读写授权
配置认证和授权,只能在服务器上进行,不能通过远程客户端进行
智能HTTP协议通过git-http-backend提供Git访问服务
Git 中,如何更新 file1.txt,将其从暂存区域移回工作目录?
`git reset file1.txt`
`git rm file1.txt`
`git reset --force file1.txt`
`git mv file1.txt`
为什么要使用 Git 垃圾回收功能?
为了避免存储不必要的信息或通过网络发送信息
为了保证存储库的一致性
为了加速提交
为了避免同一分支指向多个提交的问题
关于下方代码描述错误的是?```private static void CreateCommand(string queryString,string connectionString){ using (SqlConnection connection = new SqlConnection(connectionString)) { SqlCommand command = new SqlCommand(queryString, connection); command.Connection.Open(); command.ExecuteNonQuery(); }}```
创建一个 SqlConnection 和一个 SqlCommand
SqlConnection 设置为打开状态
ExecuteNonQuery 传递了一个连接字符串和一个作为 Select 语句的查询字符串
ExecuteNonQuery() 返回受影响的行数
分析以下的数组、list以及范型数组的定义,输出结果正确的是?```public class GenericTest { public static void main(String[] args) { List<Integer> intLinkedArrayList = new ArrayList<>(); //declare intArray List<String> strArrayList = new ArrayList<String>[10]; //generic array String[] strArray = new String[10]; //declare array intLinkedArrayList.add(1); //put values strArrayList[0].add("Hello World!"); strArray[1] = "Hello World!"; System.out.println(intLinkedArrayList); //output System.out.println(strArrayList); System.out.println(strArray); }}```
```1Hello World!Hello World!```
无法通过编译
能通过编译,运行时抛异常
```[1][Hello World!][Ljava.lang.String;@3d012ddd```
关于 Java 的抽象方法,下列说法正确的是?
可以有方法体
没有方法体的方法
抽象类中的方法都是抽象方法
可以出现在非抽象类中
Java 的 Scanner 类中`next()`和`nextLine()`方法的区别描述错误的是?
`next()`一定要读取到有效字符后才可以结束输入
`next()`可以得到带有空格的字符串
`next()`只有输入有效字符后才将其后面输入的空白作为分隔符或者结束符
`nextLine()`以Enter为结束符,也就是说`nextLine()`方法返回的是输入回车之前的所有字符
```javaimport java.util.ArrayList;import java.util.List;public class ArrayListClass { public static void main(String[] args) { List<String> arrayList = new ArrayList<>(); arrayList.add("Hello"); arrayList.add("World"); arrayList.add(1, "Java"); arrayList.add("ArrayList"); System.out.println(arrayList); }}```执行以上代码,输出结果为?
`[Hello, World, Java, ArrayList]`
```错误: 已在该编译单元中定义ArrayList错误: 编译失败```
`[Hello, Java, World, ArrayList]`
`[Java, Hello, World, ArrayList]`
Java 中,HashSet 子类依靠什么方法区分重复元素?
`toString()`,`equals()`
`clone()`,`equals()`
`hashCode()`,`equals()`
`getClass()`,`clone()`
Java 中,用于启动新事务(或获取当前活动事务)的方法是什么?
getTransaction()
commit()
rollback()
newTransaction()
Java 的字符类型采用的是 Unicode 编码方案,每个 Unicode 码占用____个比特位。
8
16
32
64
在Java语言中,下列`Object`类的方法中,可以比较两个对象是否相等的是?
`boolean equals(Object obj)`
`protected Object clone()`
`Class<?> getClass()`
`int hashCode()`
下列关于 Java 中 Thread 类提供的线程控制方法的说法中,错误的是?
在线程A中执行线程B的join()方法,则线程A等待
线程A可以通过调用interrupt()方法来中断线程B的阻塞状态
若线程A调用方法isAlive()返回值为true,则说明A正在执行中
currentThread()方法返回当前线程的引用
Java使用什么来实现运行的多态性?
Abstraction
Encapsulation
Overloading
Overriding
下面关于 Java 字符串的说法中,正确的是?
通过 `String s1=new String("abc")` 和 `String s2="abc"`,则 `s1==s2` 为 `true`
`"abc"+"def"` 会创建三个字符串对象,第三个是 `"abcdef"`。也就是说,在Java中对字符串的一切操作,都会产生一个新的字符串对象
StringBuffer是线程安全的,它比String慢
StringBuilder是线程安全的,它比String快
下列对于 Java 中 `synchronized` 和 `java.util.concurrent.locks.Lock` 的比较,描述不正确的是?
`Lock`不能完成`synchronized`所实现的所有功能
`synchronized`会自动释放锁
`Lock`一定要求程序员手工释放,并且必须在`finally`中释放
`Lock`比`synchronized`更精确的线程语义和更好的性能
以下代码使用了 StringBuffer 的截取功能,其执行结果是?```public class StringBufferDemo { public static void main(String[] args) { StringBuffer sb =new StringBuffer(); sb.append("hello").append("world").append("java"); System.out.println(sb); String s=sb.substring(5); System.out.println(s); String ss=sb.substring(5, 10); System.out.println(ss); }}```
```helloworldjavaworldjavaworld```
```helloworldjavaworldjavaworldjava```
```helloworldjavaworldjavahelloworld```
```helloworldjavaworldhelloworld```
以下代码使用了日期转换符,若在2021年5月14日执行该程序,其正确执行结果是?```import java.util.*; public class DateDemo { public static void main(String[] args) { Date date=new Date(); String str=String.format(Locale.US,"英文月份简称:%tb",date); System.out.println(str); System.out.printf("本地月份简称:%tb%n",date); }}```
英文月份简称:May 本地月份简称:五月
英文月份简称:May 本地月份简称:May
May 五月
五月 May
Java正则表达式的Matcher类的查找方法不包括?
public boolean lookingAt()
public boolean find()
public boolean find(int start)
public int find(String name)
使用 Apache 的 Curator 框架设计一个分布式锁的代码,实现对共享资源的访问控制,以下描述正确的是?
```javapublic class DistributedLock { private static final int TIMEOUT = 5000; // 加锁的超时时间,单位 ms private static final int EXPIRE = 5000; // 锁的过期时间,单位 ms private CuratorFramework client; // ZooKeeper 客户端 private String lockPath; // 分布式锁节点路径 public DistributedLock(CuratorFramework client, String lockPath) { this.client = client; this.lockPath = lockPath; } // 获取锁 public boolean lock() { try { InterProcessMutex lock = new InterProcessMutex(client, lockPath); return lock.acquire(TIMEOUT, TimeUnit.MILLISECONDS); } catch (Exception e) { return false; } } // 释放锁 public void release() { try { InterProcessMutex lock = new InterProcessMutex(client, lockPath); lock.release(); } catch (Exception e) { // do nothing } }}```
```javapublic class DistributedLock { private static final int TIMEOUT = 5000; // 加锁的超时时间,单位 ms private static final int EXPIRE = 5000; // 锁的过期时间,单位 ms private CuratorFramework client; // ZooKeeper 客户端 private String lockPath; // 分布式锁节点路径 public DistributedLock(CuratorFramework client, String lockPath) { this.client = client; this.lockPath = lockPath; } // 获取锁 public boolean lock() { InterProcessMutex lock = new InterProcessMutex(client, lockPath); return lock.acquire(TIMEOUT, TimeUnit.MILLISECONDS); } // 释放锁 public void release() { InterProcessMutex lock = new InterProcessMutex(client, lockPath); lock.release(); }}```
```javapublic class DistributedLock { private static final int TIMEOUT = 5000; // 加锁的超时时间,单位 ms private static final int EXPIRE = 5000; // 锁的过期时间,单位 ms private CuratorFramework client; // ZooKeeper 客户端 private String lockPath; // 分布式锁节点路径 // 获取锁 public boolean lock() { try { InterProcessMutex lock = new InterProcessMutex(client, lockPath); return lock.acquire(TIMEOUT, TimeUnit.MILLISECONDS); } catch (Exception e) { return false; } } // 释放锁 public void release() { try { InterProcessMutex lock = new InterProcessMutex(client, lockPath); lock.release(); } catch (Exception e) { // do nothing } }}```
```javapublic class DistributedLock { private CuratorFramework client; // ZooKeeper 客户端 private String lockPath; // 分布式锁节点路径 public DistributedLock(CuratorFramework client, String lockPath) { this.client = client; this.lockPath = lockPath; } // 获取锁 public boolean lock() { try { InterProcessMutex lock = new InterProcessMutex(client, lockPath); return lock.acquire(TIMEOUT, TimeUnit.MILLISECONDS); } catch (Exception e) { return false; } } // 释放锁 public void release() { try { InterProcessMutex lock = new InterProcessMutex(client, lockPath); lock.release(); } catch (Exception e) { // do nothing } }}```
假定Demo类如下:```package com.jiker.ones class Demo{ private String getName() { return "nameD"; } private String getNickName() { return "nicknameD"; } }```请问下列操作中,哪个反射操作能执行所有的方法?
```Class<?> aClass = Class.forName("com.jiker.ones.Demo");Method[] methods = aClass.getDeclaredMethods();for (Method method:methods){ method.setAccessible(true); System.out.println(method.invoke(new Demo()));}```
```Class<?> aClass = Class.forName("com.jiker.ones.Demo");Method[] methods = aClass.getMethods();for (Method method:methods){ method.setAccessible(true); System.out.println(method.invoke(new Demo()));}```
```Class<?> aClass = Class.forName("com.jiker.ones.Demo");Method[] methods = aClass.getDeclaredMethods();for (Method method:methods){ System.out.println(method.invoke(new Demo()));}```
```Class<?> aClass = Class.forName("com.jiker.ones.Demo");Method[] methods = aClass.getMethods();for (Method method:methods){ System.out.println(method.invoke(new Demo()));}```
请阅读下面Java代码:```public class BoxingUnboxing { public static void main(String[] args) { Integer a = 100; Integer b = 100; Integer c = 200; Integer d = 200; System.out.println(a == b); System.out.println(c == d); System.out.println(c.equals(d)); }}```下列哪个选项是这段代码正确的运行结果?
```truetruetrue```
```truefalsetrue```
```falsefalsetrue```
```truetruefalse```
在计算型任务场景中,为了保证 Java 线程池运行效率最快,以下哪种调优思路是正确的?
最大线程数越大越好
最大最小跟核心线程数配置都控制到100
最大线程100 最小线程数1 等待队列无限大
最大最小跟核心线程数配置跟CPU核数保持一致
Java 的 PhantomReference 类实现虚引用。虚引用的目的是什么?
引入虚引用的目的是能在关联的对象被收集器回收时收到一个系统通知
引入虚引用的目的是系统要发生内存溢出异常之前,会把这些虚引用关联的对象列进回收范围,进行回收,释放内存空间
引入虚引用的目的是在下一次垃圾收集之时回收掉虚引用关联的对象,以释放内存
引入虚引用的目的是获取对象实例
Java 中哪个关键字可以抛出异常?
throw
public
static
finally
以下有关于构造方法,正确的是?
一个类的构造方法可以有多个
构造方法在类定义时被调用
构造方法只能由对象的其他方法调用
构造方法可以和类同名,也可以和类不同名
JVM的基本结构中,用来存储对象的区域属于哪个组成部分?
类加载器
执行引擎
内存区
本地方法调用
JVM内存不包含如下哪个部分?
Heap
Heap Frame
PC寄存器
Stacks
一个类变量的定义为`(public static int value = 123;)`,在类加载准备阶段,value的值是?
123
0
65535
变量还未分配内存
下列对JVM垃圾回收描述错误的是?
JAVA本身是有垃圾回收机制的,需要手动激活才会执行垃圾回收操作
垃圾回收线程会对没有人指向的实例对象给回收掉,从内存里清除,让他不在占用内存资源
垃圾回收期正对的是对象,而不是变量
JVM是否进行类的垃圾回收可以通过Xnoclasgc参数进行设置
JVM 分代模型中,老年代内存对象空间超过默认_____%的阈值,就会触发 fullgc 。
80
95
92
85
下列 jstat 选项中,代表监视新生代 GC 状况的选项是?
-class
-gcold
-compiler
-gcnew
JVM 内存区域主要分为线程私有区域【程序计数器、虚拟机栈、本地方法区】、线程共享区域【 JAVA 堆、方法区】、直接内存。 其中最不可能出现内存溢出的区域是?
虚拟机栈
程序计数器
本地方法区
直接内存
哪个组件负责将字节码转换为机器特定的代码?
JVM
JDK
JSP
JRE
下列哪一个方法用于告诉调用线程放弃监视器并进入睡眠状态,直到其他线程进入同一个监视器?
`wait()`
`notify()`
`notifyAll()`
`sleep()`
```public class OnTest { public static void main(String[] args) { testError(1); } public static void testError(int depth) { depth++; testError(depth); }}```请问运行代码后会抛出什么异常?
java.lang.StackOverflowError
java.util.StackOverflowError
java.lang.OutOfMemoryError
java.util.OutOfMemoryError
Java虚拟机对动态类型语言的支持是因为JDK7新增的哪个字节码指令?
`invokespecial`
`invokedynamic`
`invokeinterface`
`invokevirtual`
Java中的`final`方法是使用哪个指令调用的?
`invokevirtual`
`invokedynamic`
`invokespecial`
`invokestatic`
如果 Java 应用出现死锁,最常用的诊断工具是什么?
jmap
jstat
jstack
jcmd
在 JVM 的垃圾回收中,若老年代的对象存活率过高会导致什么?
增加 Full GC 的频率
减少内存使用
提高应用性能
降低 CPU 使用率
如何生成JVM的堆转储文件?
`jstack -dump`
`jmap -dump`
`jstat -dump`
`jcmd -dump`
Kafka 中,以下哪个错误可以通过消息重发解决?
no leader 错误
消息大小的错误
认证错误
序列化错误
关于 Kafka 消息保留的时间,以下描述错误的是?
log.retention.ms和log.retention.hours同时进行配置,以最后一个参数的顺序为准,会覆盖前一个参数的配置
kafka默认保留消息的时间是7天
kafka默认保留消息的时间是168小时
log.retention.ms和log.retention.hours的作用是一样的
Kafka中的LEO代表?
一个分区中所有副本最小的offset
每个副本的最后一条消息的offset
一个分区中所有副本最小的offset+1
每个副本的最后一条消息的offset+1
对于选型Kafka还是RabbitMQ,通常最重要的是哪项指标?
吞吐量
有序性
丢失率
稳定性
Kafka中,消费者组的作用是什么?
允许多个消费者实例同时消费同一个主题的消息
确保每个消息只被消费一次
监控消费者实例的健康状态和性能
关于 partition 中的数据是如何保存到硬盘上的,说法错误的是?
一个 topic 分为好几个 partition,每一个 partition 是以文件夹的形式保持在 broker 节点上面的
每一个分区的命名是从序号 0 开始递增
每一个 partition 目录下多个 segment 文件(包含xx.index,xx.log),默认是 1G
每个分区里面的消息是有序的,数据是一样的
zookeeper集群服务用于 follower 节点的通信端口号是多少?
2888
3888
2181
4888
以下选项关于提升 Kafka 吞吐量的操作错误的是?
适当增加`num.replica.fetchers`
采用多实例`consumer`
如果分区数很多,可以增加`buffer.memory`的值
减小`linger.ms`的值
在Kafka中,日志清理保存的策略包括?
日志段文件大小限制(Log Segment Size Limit)
日志保留时间(Log Retention Time)
日志压缩(Log Compaction)
其他三项都是
Kafka中的消息重平衡是什么?
消息在分区之间的重新分配
消息在分区中的重新排序
消息在分区中的重新压缩
消息在分区中的重新传输
关于Kafka的分区机制,以下说法正确的是?
Kafka的分区是指将一个Topic划分为多个子Topic,每个子Topic可以有不同的配置和属性
Kafka的分区可以提高Topic的并行度和吞吐量,每个分区可以由不同的消费者组并发消费
Kafka的分区不能保证数据的顺序性,每个分区内部按照消息的时间戳顺序存储和消费
Kafka的分区可以动态增加或减少,根据数据量和业务需求进行调整
Kafka的消息存储是基于什么机制实现的?
文件系统
数据库
内存
索引
Kafka中,以下哪个配置参数可以控制生产者发送消息的可靠性?
acks
retries
linger.ms
compression.type
在Kafka中,当Zookeeper宕机时会发生什么?
Kafka集群无法正常工作
Kafka可以继续工作但无法进行新的操作
Kafka无法发送数据给消费者
Kafka可以创建新的主题但无法读写旧主题
在 Kafka 体系结构中,zookeeper 可以通过哪种类型的组件来实现集群的元数据管理和协调?
节点(Node)
会话(Session)
监听器(Watcher)
选举器(Elector)
下列关于 Linux 无名信号量的描述,哪个选项是错误的?
使用 sem_init() 创建信号量
通常用于线程间同步互斥
对其的访问都是原子操作
仅支持阻塞操作
以下关于 Linux 内核中自旋锁的描述,哪个选项是错误的?
自旋锁不会引起调用者睡眠
自旋锁可以递归
自旋锁的忙等待浪费了处理器的时间
在单处理器系统中,自旋锁不起锁的作用
关于Linux系统的负载(Load),以下描述不正确的是?
可以通过就绪和运行的进程数来间接反映
可以通过find命令查看
可以通过TOP命令查看
Load:2.5,1.3,1.1表示系统的负载压力在逐渐减少
在 Linux 系统中,进程的调度算法是基于什么因素来决定的?
进程的优先级和时间片
进程的状态和类型
进程的内存占用和CPU使用率
进程的创建时间和PID
假设在一个多进程的 Linux 网络服务器程序的开发中,想要使用共享内存来实现进程间的数据交换,那么需要使用哪些系统调用来创建和访问共享内存?
shmget 和 shmat
mmap 和 munmap
pipe 和 dup
socketpair 和 sendmsg
MyBatis指定配置文件的根元素使用的是?
`<sqlMapConfig>`
`<configuration>`
`<setting>`
`<environments>`
MyBatis的```<foreach>```包含下列哪些属性?1.item 2.index 3.open 4.suffixOverrides
1、2、3
2、3、4
1、2、4
1、2、3、4
在开发中如何自定义一个String类型的`typehandler`类型处理器? 1.实现接口 `typeHandler`,或者继承 `BaseTypeHandler`2.在配置文件中配置自定义`typehandler`类型处理器```<typeHandlers> <typeHandler jdbcType="VARCHAR" javaType="string" handler="自定义类限定名"/></typeHandlers>``` 3.在mapper.xml中使用```<resultMap id="roleMapper" type="role"> <result property="note" column="note" typeHandler="自定义类限定名"/></resultMap>``` 4.自定义typeHandler无法进行包扫描的形式注入
1、2、3
2、3、4
1、2、4
1、3、4
MyBatis关于where-if组合动态标签使用错误的是?1. ```<where>```标签的作用主要是替换sql语句中的where2. ```<where>```标签后有成立的条件,会在sql后拼接where语句3. ```<if>```标签可以去除第一个子句条件开头的 “AND” 或 “OR”,```<where>```则不会去除。4. ```<where>```标签可以去除第一个子句条件开头的 “AND” 或 “OR”,```<if>```则不会去除。
1、2
1、2、3
3
1、3
当结果集中值为 null 时,调用映射对象的 setter(map 对象时为 put)方法的配置为?
```<settings> <setting name="safeRowBoundsEnabled" value="true" /></settings>```
```<settings> <setting name="mapUnderscoreToCamelCase" value="false" /></settings>```
```<settings> <setting name="mapUnderscoreToCamelCase" value="true" /></settings>```
```<settings> <setting name="callSettersOnNulls" value="true" /></settings>```
关于 MyBatis 二级缓存,下面说法错误的是?
在SqlSessionFactory层面上设置二级缓存提供各个对象SqlSession
二级缓存默认是开启的,不需要进行配置
二级缓存的配置只需要在XML配置即可,或者指定算法,刷新时间间隔,缓存状态,大小等
二级缓存默认是不开启的,需要进行配置
在MyBbatis中,现有如下需求:当type == x1 时和type == x2时where中的判断条件不同,如何编写sql?
```<select id = "" resultMap = ""> select * from table <where> <if test="type == 'x1' "> and 条件1; </if> <if test="type == 'x2' "> and 条件2; </if> </where></select>```
```<select id = "" resultMap = ""> select * from table <where> <choose test="type == 'x1' "> and 条件1; </choose> <choose test="type == 'x2' "> and 条件2; </choose> </where></select>```
```<select id = "" resultMap = ""> select * from table <where> <if test="type = 'x1' "> and 条件1; </if> <if test="type = 'x2' "> and 条件2; </if> </where></select>```
```<select id = "" resultMap = ""> select * from table <where> <choose test="type = 'x1' "> and 条件1; </choose> <choose test="type = 'x2' "> and 条件2; </choose> </where></select>```
动态SQL`<choose>`标签中关于`<otherwise>`标签描述正确的是?
<otherwise>标签可以有0个
<otherwise>标签至少有1个
<otherwise>标签可以有2个
其他都不对
在MyBatis动态SQL中,可以在if标签的test属性中通过哪个关键字组合多个条件,使得多个条件同时满足时if中的语句生效?
and
or
not
set
在MyBatis配置文件中,当需要将数据库连接参数提取到外部properties文件中统一管理时,下列哪种配置方式是正确的?
在核心配置文件中使用`<properties>`标签直接写入数据库连接参数
通过`<properties resource="db.properties"/>`引入文件,并用`${key}`引用属性
将`<properties>`标签嵌套在`<environments>`标签内部声明参数
在映射文件中使用`<property name="url" value="jdbc:mysql://..."/>`定义参数
在用户批量查询接口中,动态SQL如下: ```xml <select id="selectUsersByIds"> SELECT * FROM users WHERE id IN <foreach collection="ids" item="id" open="(" separator="," close=")"> #{id} </foreach> </select> ``` 当传入的ids参数为空集合时,生成的SQL语句为`SELECT * FROM users WHERE id IN`,导致语法错误。应如何修改?
在foreach外层添加`<if test="ids != null and !ids.isEmpty()">`条件判断
将`WHERE`改为`WHERE 1=1`,保留原有foreach逻辑
在foreach的open属性中增加默认值0,改为`open="(0,"`
将foreach的close属性改为`close=" OR 1=1)"`
在一套多微服务部署的用户管理系统中,数据库表 `t_user` 中的字段 `profile_json` 存储了用户的附加资料(以 JSON 格式存储)。项目组在 MyBatis 中为此字段编写了一个自定义类型处理器 `JsonProfileTypeHandler`,用于在查询时将数据库中的 JSON 数据反序列化为 Java 类 `Profile`,并在插入或更新时将 `Profile` 序列化为 JSON 字符串。以下是部分 `UserMapper.xml` 配置,其中 `/* 代码缺失 */` 处需要完成 `resultMap` 对 `profile` 属性的映射,并指定使用自定义类型处理器。请从下列四个选项中选出正确的填充代码:```xml<mapper namespace="com.example.mapper.UserMapper"> <resultMap id="UserResultMap" type="com.example.model.User"> <id property="id" column="id"/> <result property="username" column="username"/> <!-- 其他字段映射省略 --> <!-- 代码缺失 --> </resultMap> <select id="findUserById" parameterType="long" resultMap="UserResultMap"> SELECT id, username, profile_json FROM t_user WHERE id = #{id} </select></mapper>```
```xml<result property="profile" column="profile_json" javaType="com.example.model.Profile" typeHandler="com.example.typehandler.JsonProfileTypeHandler"/>```
```xml<association property="profile" javaType="com.example.model.Profile" column="profile_json"/>```
```xml<collection property="profile" ofType="com.example.model.Profile"> <result column="profile_json"/></collection>```
```xml<result property="profile" column="profile_json" javaType="string"/>```
在某会员管理系统中,需要删除超时未登录且状态标记为“INACTIVE”的会员账号。以下是 `MemberMapper.xml` 中的部分代码,其中 `/* 代码缺失 */` 处应基于 `<if>` 标签的 `test` 属性来控制 SQL 条件的拼接,以保证只删除状态匹配且满足超时天数条件的用户。请从下列四个选项中选出正确的填充代码:```xml<mapper namespace="com.example.mapper.MemberMapper"> <delete id="deleteInactiveMembers" parameterType="java.util.Map"> DELETE FROM t_member <where> /* 代码缺失 */ </where> </delete></mapper>```
```xml<if test="status == 'INACTIVE' and daysSinceLastLogin >= 30"> status = 'INACTIVE' AND last_login <= DATE_SUB(NOW(), INTERVAL 30 DAY)</if>```
```xml<if> status = 'INACTIVE' AND last_login <= DATE_SUB(NOW(), INTERVAL 30 DAY)</if>```
```xml<if test="status == 'ACTIVE' or daysSinceLastLogin < 30"> status = 'INACTIVE' AND last_login <= DATE_SUB(NOW(), INTERVAL 30 DAY)</if>```
```xml<if test="status != null"> AND status = 'INACTIVE' OR last_login <= DATE_SUB(NOW(), INTERVAL 30 DAY)</if>```
关于 MySQL 覆盖索引的说法,下列不恰当的是?
索引条目通常远小于数据行的大小,所以如果只需要读取索引,那么MySQL就会极大地减少数据访问量
因为索引是按照列值顺序存储的(至少在单个页内是如此),所以对于I/O密集型的范围查询会比随机从磁盘读取每一行数据的I/O要少得多
一些存储引擎比如MyISAM在内存中只缓存索引,数据则依赖于操作系统来缓存,因此要访问数据需要一次系统调用
由于InnoDB的聚簇索引,覆盖索引对InnoDB表支持不好
维护数据表的目的不包括?
找到并修复损坏的表,减少碎片
维护准确的索引统计信息
减少碎片
保持数据量的增长
MySQL 中,创建表的时候,使用哪个关键字可以创建全文索引?
FROM
WHERE
FULLTEXT
ENGINE
MySQL 中创建索引的目的是?
提高查询的检索性能
归类
创建唯一索引
创建主键
```mysqlselect right('学习mysql', 5);```输出的结果为?
学习
mysql
学
习
关于索引,下列哪一项是正确的?
索引会减慢插入速度,但会加快查询速度
索引会减慢查询速度,但会加快插入速度
索引只能在主键列上完成
索引只能在包含数值数据的列上完成
如何使用SQL删除人员表中`FirstName`是`Peter` 的记录?
```DELETE FROM Persons WHERE FirstName = 'Peter';```
```DELETE ROW FirstName='Peter' FROM Persons;```
```DELETE FirstName='Peter' FROM Persons;```
其它几项都是错的
MySQL 中,在视图上不能完成的操作是?
查询
定义新的视图
更新视图
定义新的表
在MySQL中,如果要在一个大表上添加一个索引,但是不想影响表的读写性能,应该采用哪种方法?
直接在旧表上使用ALTER TABLE语句添加索引
新建一个表,结构和旧表一样,然后使用INSERT INTO ... SELECT ... 语句将旧表数据复制到新表,并在新表上添加索引,最后重命名新旧表
新建一个表,结构和旧表一样,然后使用REPLACE INTO ... SELECT ... 语句将旧表数据复制到新表,并在新表上添加索引,最后重命名新旧表
新建一个表,结构就是要修改后的结构,在旧表上建立触发器,旧表更新数据时同步到新表,把旧表数据复制到新表,数据同步完成后,执行重命名操作,交换新旧表,删除旧表及触发器
静态游标和动态游标的区别是什么?
静态游标只能向前滚动,动态游标可以向前和向后滚动
静态游标只能读取结果集的快照,动态游标可以读取结果集的实时数据
静态游标只能用于只读操作,动态游标可以用于更新操作
静态游标只能在存储过程中使用,动态游标可以在任何SQL语句中使用
假设你有一个名为students的表,它有两个列:name和grade,分别存储学生的姓名和成绩。表中的数据如下:| name | grade ||------|-------|| 张三 | 90 || 李四 | 80 || 王五 | 85 |你想用SELECT语句查询表中的数据,并按照姓名的拼音顺序排序。你应该怎么写这个查询?
`SELECT name, grade FROM students ORDER BY name;`
`SELECT name, grade FROM students ORDER BY CONVERT(name USING gbk);`
`SELECT name, grade FROM students ORDER BY CONVERT(name USING utf8);`
`SELECT name, grade FROM students ORDER BY CONVERT(name USING pinyin);`
假设你有一个名为articles的表,它有两个列:title和content,分别存储文章的标题和内容。表中的数据如下:| title | content ||-------|---------|| MySQL全文索引介绍 | 本文介绍了MySQL的全文索引的概念、用法和限制 || MySQL分布式事务实践 | 本文介绍了MySQL的分布式事务的原理、操作和风险 || MySQL字符集设置教程 | 本文介绍了MySQL的字符集的作用、影响和配置 |你想用SELECT语句查询表中的数据,并按照标题或内容中包含“MySQL”这个词的频率降序排序。你应该怎么写这个查询?
`SELECT title, content FROM articles ORDER BY MATCH(title, content) AGAINST('MySQL') DESC;`
`SELECT title, content FROM articles ORDER BY MATCH(title, content) AGAINST('MySQL' IN BOOLEAN MODE) DESC;`
`SELECT title, content FROM articles ORDER BY MATCH(title) AGAINST('MySQL') + MATCH(content) AGAINST('MySQL') DESC;`
`SELECT title, content FROM articles ORDER BY MATCH(title) AGAINST('MySQL' IN BOOLEAN MODE) + MATCH(content) AGAINST('MySQL' IN BOOLEAN MODE) DESC;`
MySQL中,将user_id为2001的stu表中学生的地址修改为‘北京’,分数改为100。正确的语句是?
`update stu set address = '北京',score=100 where id = 2001`
`update stu set address = 北京,score=100 where id = 2001`
`update stu set address = '北京',score='100' where id != 2001`
`set stu set address = '北京',score=100 where id = 2001`
在一个高可用的MySQL数据库系统中,为了提高查询性能和数据一致性,团队决定使用视图来合并来自多个表的数据。以下是创建视图的SQL代码片段,但关键部分缺失。请从下列选项中选择正确的代码片段以完成这个视图的创建。```sqlCREATE VIEW CombinedData ASSELECT a.id, a.name, b.amount, c.statusFROM Orders aJOIN Payments b ON a.id = b.order_idJOIN Shipping c ON a.id = c.order_id/* 代码缺失 */WHERE c.status = 'Shipped';```
```sqlLEFT JOIN CustomerDetails d ON a.customer_id = d.id```
```sqlINNER JOIN CustomerDetails d ON a.customer_id = d.id```
```sqlRIGHT JOIN CustomerDetails d ON a.customer_id = d.id```
```sqlFULL OUTER JOIN CustomerDetails d ON a.customer_id = d.id```
假设有一个电商网站,有以下几个表:- 用户表(user_id, name, email, phone, address)- 商品表(product_id, name, description, price, stock)- 订单表(order_id, user_id, order_time, order_status, total_amount)- 订单明细表(order_detail_id, order_id, product_id, quantity, unit_price)下列关于上述表设计的说法中,哪一个是正确的?
这些表的设计符合关系数据库的第三范式(3NF)的要求
在订单明细表中,包含了商品表中的价格字段,这是一种范式化的设计,能够提高查询效率
这些表的设计不符合关系数据库的任何标准范式
这些表的设计符合关系数据库的第一范式(1NF)和第二范式(2NF)的要求,但不符合第三范式(3NF)的要求
B+树索引和哈希索引的区别,哪个是错的?
如果是等值查询,哈希索引明显有明显优势
哈希索引适合范围查询检索
B+树索引的关键字检索效率比较平均
在大多数场景下,都会有范围查询、排序、分组等查询特征,用 B+树索引就可以了
当删除MySQL表中的数据时,索引如何变化?
删除操作会自动更新索引,以反映数据的变更
必须手动重建索引,删除操作后索引不会自动更新
索引文件不受删除操作影响,因此无需任何改动
索引会在下一次服务器重启时自动更新
下面关于命令 `redis-cli -h 10.122.10.23 -p 6379 -a "123456"` 描述正确的是?
连接的服务器ip是 10.122.10.23
服务器的端口是 6379
服务器密码是 123456
其他都正确
下面关于 Redis 的INCR和DECR描述错误的是?
当k不存在,INCR k 会先初始化k的值为 0,然后再执行INCR操作
当k不存在,DECR k 会先初始化k的值为 1,然后再执行DECR操作
如果k的值不能表示为整数数字,INCR、DECR都会返回错误
INCR、DECR操作成功之后,返回当前k的值
下面命令执行完毕之后,将输出什么?```SADD course "java" "php" "python"SADD course "go" "ruby"SPOP courseSISMEMBER course "go"```
1
0
1或者0
其他都不正确
对下面 Redis 命令执行过程描述正确的是?```PFADD ip5 "10.10.10.3" "192.168.10.4" "10.10.3.1" "10.10.3.2"PFADD ip5 "10.19.19.1" "10.10.10.3" "10.10.3.2"PFADD ip6 "19.21.10.3" "19.21.10.3" "19.10.21.4" "10.10.3.2"PFADD ip6 "10.10.10.3" "10.10.3.1" "10.10.3.10"PFCOUNT ip5 ip6PFMERGE ip ip5 ip6PFCOUNT ip ```
PFCOUNT ip5 ip6 输出 ip5 ip6近似基数之和
PFMERGRE 获取两个集合的交集
两次PFCOUNT 输出的值都是 8
PFCOUNT ip 输出 3
下列哪个选项不是Redis 过期键的删除策略?
被动删除
定时删除
懒惰删除
备份删除
下面关于Redis描述错误的一项是?
Master最好不要做任何持久化工作,如RDB内存快照和AOF日志文件
主从复制不要用单向链表结构,用图状结构更为稳定
如果数据比较重要,某个Slave开启AOF备份数据,策略设置为每秒同步一次
为了主从复制的速度和连接的稳定性,Master和Slave最好在同一个局域网内
Redis 消费者组相关命令中将消息标记为“已处理”的是?
XACK
XGROUP
XCLAIM
XINFO
Redis中,对一个 key 执行 INCR 命令会发生什么?
会将对应的value+1
会报错,因为Redis没有int类型
会报错,因为Redis没有long类型
会报错,因为Redis没有浮点数类型
假设正在开发一个在线游戏的排行榜系统,使用Redis的有序集合(Sorted Set)来存储玩家的得分信息。在更新玩家得分并处理可能的排名变化时,以下哪个命令是正确的?
`ZADD leaderboard_scores score username`
`ZADD leaderboard_scores NX score username`
`ZADD leaderboard_scores CH score username`
`ZADD leaderboard_scores INCRBY score username`
对于`Redis`的散列数据类型(`HASH`),以下哪个命令可以同时设置多个字段的值?
`HGETALL`
`HSET`
`HMSET`
`HSETNX`
Redis HyperLogLog 是一种用于统计基数的数据结构,它可以在极小的空间内存储大量的元素。假设有一个 HyperLogLog 键名为 hll,已经存储了一些元素,那么以下哪个命令可以将 hll 的基数估算值与另一个 HyperLogLog 键名为 hll2 的基数估算值相加,并将结果存储到一个新的 HyperLogLog 键名为 hll3 中?
PFADD hll3 hll hll2
PFMERGE hll3 hll hll2
PFCOUNT hll3 hll hll2
PFUNION hll3 hll hll2
在Redis哈希(Hash)数据类型中,以下哪种操作不会修改哈希表的内部数据结构或内容?
`HSET key field value`
`HDEL key field`
`HGET key field`
`HINCRBY key field increment`
假设需要实现一个计数器,要求能够对计数器进行加1和减1操作,并且能够获取当前计数器的值,以下哪个选项不适合用于实现该计数器?
使用Redis的INCR命令,将计数器的值存储为一个整数类型的键值对
使用Redis的DECR命令,将计数器的值存储为一个整数类型的键值对
使用Redis的INCRBYFLOAT命令,将计数器的值存储为一个浮点数类型的键值对
使用Redis的APPEND命令,将计数器的值存储为一个字符串类型的键值对
在Redis中, 如果尝试去获取一个不存在的键的值时,会获取到什么?
返回错误
返回nil
返回键不存在的异常
返回未知
在Redis中,以下命令用于向HyperLogLog中添加一个元素的是?
PFADD
HLLADD
LADD
SETADD
假设在一个电商应用中需要实现一个商品排行榜功能,要使用Redis的有序集合来存储商品的销量和排名,同时需要保证Redis的性能和可用性,应该如何正确配置Redis服务器?
使用appendonly yes命令开启AOF持久化,然后使用ZINCRBY命令更新商品的销量和排名,最后使用ZREVRANGE命令查询排行榜
使用save 60 1000命令开启RDB持久化,然后使用ZADD命令更新商品的销量和排名,最后使用ZRANK命令查询排行榜
使用cluster yes命令开启集群模式,然后使用ZSCORE命令更新商品的销量和排名,最后使用ZRANGE命令查询排行榜
使用maxmemory 1gb命令设置内存上限,然后使用ZREM命令更新商品的销量和排名,最后使用ZCARD命令查询排行榜
在使用Redis管理大规模用户积分排行榜时,确保数据的安全性与恢复能力至关重要。为了满足高效备份和快速恢复的要求,以下哪种策略是合适的?
使用 SAVE 命令进行同步备份,每隔一小时执行一次,以确保数据的定期保存
使用 BGSAVE 命令进行异步备份,并禁用自动保存配置,以减少备份对服务器性能的影响,同时通过 RDB 文件进行快速恢复
使用 GET 命令获取所有用户积分数据,并将其存储在外部数据库中,以备份数据并确保恢复时的数据完整性
使用 EXPIRE 命令为每个用户积分键设置过期时间,以确保数据不会无限期增长,进而实现数据的自动管理和备份
在Redis中,下列关于事务的一些描述,正确的是?
`Redis`的事务是一组命令的原子性操作
`Redis`的事务支持跨多个数据库的操作
`Redis`的事务在执行期间可以修改其他客户端的数据
`Redis`的事务是保证并发安全的,无需考虑并发冲突
以下哪个不是Redis支持的数据类型?
string
hash
array
set
在Redis中,可以使用一些命令来操作键和列表。假设有一个键叫做mylist,它对应的值是一个列表,其中存储了一些字符串。以下关于键和列表的命令描述错误的是?
使用LLEN mylist命令可以返回列表的长度,即元素的个数
使用LPOP mylist命令可以返回并删除列表的第一个元素
使用LPUSH mylist "hello"命令可以将字符串"hello"插入到列表的最后一个位置
使用EXPIRE mylist 10命令可以设置键mylist在10秒后过期,即被删除
在一个高并发的社交媒体应用中,需要使用Redis列表(List)来实现用户的个人动态流功能。该功能需要满足以下要求:1. 支持每秒钟数十万次的写入操作2. 每个用户的动态流最多保留1000条最新动态3. 支持分页读取,每页20条4. 需要能够高效地删除指定的动态5. 系统内存有限,需要考虑存储效率考虑到这些要求,以下哪种Redis列表(List)的使用方式最适合这个场景?
使用LPUSH插入新动态,LRANGE获取分页数据,LREM删除指定动态,定期使用LTRIM保持列表长度
使用RPUSH插入新动态,使用LINDEX遍历列表来实现分页,LSET修改动态内容,RPOP删除旧动态
将每条动态存为单独的字符串,使用MSET批量插入,MGET批量读取,DEL删除指定动态,使用有序集合(Sorted Set)存储动态ID和时间戳
使用RPUSH插入新动态,LRANGE获取分页数据,定期将列表中的数据迁移到持久化存储,只在Redis中保留最近一周的动态
考虑到Redis集合数据类型的特性和操作命令,以下哪段Python脚本正确地实现了向集合添加元素并检查某个元素是否存在于集合中的操作?
```pythonimport redisr = redis.Redis()r.sadd("myset", "element1", "element2")exists = r.sismember("myset", "element1")```
```pythonimport redisr = redis.Redis()r.set("myset", "element1")exists = r.sismember("myset", "element1")```
```pythonimport redisr = redis.Redis()r.sadd("myset", ["element1", "element2"])exists = r.sismember("myset", "element1")```
```pythonimport redisr = redis.Redis()r.sadd("myset", "element1", "element2")exists = r.exists("myset", "element1")```
Redis命令中,哪个命令可以用来创建一个HyperLogLog结构?
HLLADD
HLLCREATE
PFADD
PFCREATE
假设有一个Redis HyperLogLog,其key为visitors,用来统计某个网站的访问量,每个访问者的IP地址对应一个字符串。现在有以下命令执行:```PFADD visitors 192.168.1.1 192.168.1.2 192.168.1.3PFADD visitors 192.168.1.4 192.168.1.5GET visitors```请问,最后一条命令的输出是什么?
`(error) WRONGTYPE Operation against a key holding the wrong kind of value `
`(nil)`
`5`
`visitors`
下列哪项属于 Redis 脚本的安全限制?
Redis 脚本不能执行危险的命令,如 FLUSHALL, SHUTDOWN 等
Redis 脚本不能执行长时间的操作,如 SORT, KEYS 等
Redis 脚本不能执行随机的操作,如 RANDOMKEY, SPOP 等
Redis 脚本不能执行复杂的操作,如 GEOADD, ZUNIONSTORE 等
在一个高可用的Redis集群环境中,除了基本的主从复制,还需要进行一些配置来确保Redis数据的持久性和高可用性,则以下哪项是正确的?
```appendonly yesappendfsync everysec```
```save 900 1save 300 10save 60 10000```
```appendonly yesappendfsync alwaysreplicaof <master-ip> <master-port>```
```maxmemory 2gbmaxmemory-policy allkeys-lru```
假设需要在Redis中存储一个键,该键的值是一个字符串,想要设置该键的过期时间为10秒,并且在过期之前可以修改该键的值,应该使用什么命令来实现这个需求?
使用SET命令存储键和值,使用EXPIRE命令设置过期时间,使用SET命令修改值,例如:SET key valueEXPIRE key 10SET key new_value
使用SETEX命令存储键和值,并同时设置过期时间,使用SETEX命令修改值,例如:SETEX key 10 valueSETEX key 10 new_value
使用SETNX命令存储键和值,使用EXPIREAT命令设置过期时间,使用SETNX命令修改值,例如:SETNX key valueEXPIREAT key 10SETNX key new_value
使用MSET命令存储键和值,使用PEXPIRE命令设置过期时间,使用MSET命令修改值,例如:MSET key valuePEXPIRE key 10000MSET key new_value
在设计一个基于Redis的用户会话(session)管理系统时,我们需要考虑如何组织和存储会话数据。以下哪种方案能够高效地管理和访问用户会话信息,并尽可能减少内存的使用?
为每个用户的会话数据创建一个字符串键,键名为“session:用户ID”,键值为会话数据的JSON字符串
为每个用户的会话数据创建一个哈希(hash)键,键名为“session:用户ID”,哈希的字段对应会话数据的不同属性
使用一个全局的字符串键“sessions”来存储所有用户的会话数据,键值为包含所有会话数据的JSON字符串
使用一个全局的列表(list)键“session_list”来存储所有用户的会话数据,列表的每个元素为一个包含用户ID和会话数据的JSON字符串
Redis HyperLogLog的底层数据结构是哪一项?
数组
链表
集合
二叉树
下列对 Redis 中键的描述,错误的是?
键(Key)是用来唯一标识存储在内存中的数据的
Redis的键是在一个全局命名空间中
不能用"user:123:name"来作为Redis的键,因为其中有特殊字符
Redis的键可以有一个可选的生命周期
假设正在开发一个网站,需要统计每天的访问量,并且实时推送给后台管理人员。使用Redis HyperLogLog来存储每天的访问量,使用Redis发布订阅来实现实时推送。部分代码如下:```pythonimport redisimport time# 创建一个redis连接对象r = redis.Redis(host='localhost', port=6379, db=0)# 定义一个函数,用于生成当天的HyperLogLog键名def get_hll_key(): return 'hll:' + time.strftime('%Y-%m-%d')# 定义一个函数,用于向HyperLogLog中添加访问者的IP地址def add_visitor(ip): r.pfadd(get_hll_key(), ip)# 定义一个函数,用于获取当天的访问量def get_visit_count(): return r.pfcount(get_hll_key())# 定义一个函数,用于发布当天的访问量到指定的频道def publish_visit_count(channel): /* 代码缺失 */```请问,/* 代码缺失 */处应该填写哪一行代码?
`r.publish(channel, get_visit_count())`
`r.pubsub(channel, get_visit_count())`
`r.subscribe(channel, get_visit_count())`
`r.pfmerge(channel, get_visit_count())`
一个在线视频网站想统计每个视频的独立观看用户数量以及每日的独立访问用户数量。为了减少存储空间,决定使用Redis的Bitmaps和HyperLogLog数据类型。使用Bitmaps来跟踪每个视频的观看记录,每个用户对应Bitmaps的一个位。使用HyperLogLog来估算每日的独立访问用户数量。请补全以下代码以满足我们的需求。选项中哪段代码是正确的?```pythonimport redisr = redis.Redis(host='localhost', port=6379, db=0)def mark_video_watched(user_id, video_id): r.setbit(video_id, user_id, 1) /* 代码缺失 */```
```pythonr.pfadd("daily_unique_visitors", user_id)```
```pythonr.hset("daily_unique_visitors", user_id, 1)```
```pythonr.pfadd(user_id, "daily_unique_visitors")```
```pythonr.setbit("daily_unique_visitors", user_id, 1)```
直接使用JDBC对数据进行访问的优点是?
JDBC不依赖于任何框架,学习成本低
JDBC能更好地对数据访问的性能进行优化
JDBC可以使用数据库的所有特性
其他都是
事务隔离级别中性能最差的是?
串行化
未提交读
已提交读
可重复读
可能出现脏读的隔离级别是?
未提交读
已提交读
可重复读
串行化
关于传播行为:`PROPAGATION_REQUIRED`下列说法正确的是?
表示如果当前存在一个逻辑事务,则加入该逻辑事务,否则将新建一个逻辑事务
表示每次都创建新的逻辑事务
表示如果当前存在逻辑事务,就加入到该逻辑事务中,如果没有,就以非事务运行
表示如果当前存在逻辑事务,就把当前事务暂停,以非事务方式运行
关于传播行为:PROPAGATION\_NESTED说法正确的是?
外部事务的回滚不影响嵌套事务
嵌套事务的回滚导致外部事务回滚
外部事务的回滚导致嵌套事务的回滚
其他说法都不正确
在使用JDBCTemplate过程中,如果要将数据转换成对象,需要实现以下哪个接口?
RowMapper接口
PreparedStatementCreator接口
PreparedStatementSetter接口
都不是
Spring MVC中,如果要处理文件上传,需要定义以下哪个Bean?
CommonsMultipartResolver
BeanNameViewResolver
XmlViewResolver
TilesViewResolver
以下哪个注解可以启用Spring MVC的消息转换功能?
@ResponseBody
@RequestBody
@RestController
其他三项都可以
关于AutowireCapableBeanFactory的作用,下列说法错误的是?
它是BeanFactory的子接口
它可以将Spring管理的Bean注入到不受Spring容器管理的java对象中
用户一般不用实现该接口,只需要通过调用ApplicationContext的getAutowireCapableBeanFactory方法就可以得到该对象
ApplicationContext实现了该接口
关于Spring声明式事务,下列说法正确的是?
Spring声明式事务是通过AOP实现的
Spring声明式事务是侵入性高的编程方式
Spring声明式事务需要JavaEE容器的参与
Spring声明式事务增加了代码的书写量
关于XmlBeanDefinitionReader,下列说法错误的是?
它只能从xml文件中读取Bean的定义
它将xml文件的解析工作委托给了BeanDefinitionDocumentReader
它继承了AbstractBeanDefinitionReader
它只负责解析Bean的定义,不负责将解析过的Bean注册到Spring容器中
在Spring MVC中,如果自定义拦截器的preHandle方法返回false,以下说法正确的是?
仍然会调用Controller定义的映射方法
不会调用Controller定义的映射方法
继续执行下一个拦截器的preHandler方法
其他说法都不正确
在Spring中,如果一个类声明为final,下列说法正确的是?
无法使用CGLIB对其进行动态代理
可以使用CGLIB对其进行动态代理
可以使用JDK进行静态代理
可以使用JDK进行动态代理
在SSH整合时,事务的隔离级别由哪部分配置和管理?
java应用程序
Hibernate
数据库系统
JDBC驱动
Spring 中 IoC 使用的模式为?
单例模式
工厂模式
过滤器模式
装饰器模式
@Component注解的功能是?
将 java 类标记为 bean,是任何 Spring 管理组件的通用构造型
将一个类标记为 Spring Web 控制器,会自动导入到 IoC 容器中
组件注解的特化,在服务层类中更好指定了意图
将 DAO 导入 IoC 容器, 使未经检查的异常有资格转换为 Spring DataAccessException
Spring AOP中执行点的集合叫做?
pointcut
joinpoint
advice
weave
Spring MVC中,负责处理HTTP请求和响应的类是?
DispatcherServlet
RequestHandler
HttpServlet
SpringController
Spring MVC中注解@PathVariable的作用是?
将动态值从 URI 映射到处理程序方法参数
用于在控制器处理程序方法中配置 URI 映射
用于发送 Object 作为响应,通常用于发送 XML 或 JSON 数据作为响应
用于在 spring bean 中自动装配依赖项
`@Aspect`、`@Before`、`@After`、`@Around`、`@Pointcut`注解的作用是?
在 spring bean 中自动装配依赖项
用于切面编程(AOP)
用于配置 spring bean 的范围
用于基于 java 的配置
Spring 和 Hibernate整合的过程中,各对象注入的顺序是?
DataSource->SessionFactory->DAO->BIZ
SessionFactory->DataSource->DAO->BIZ
SessionFactory->DAO->DataSource->BIZ
DAO->SessionFactory->DataSource->BIZ
Spring AOP中处理方法抛出异常的通知类型为?
@Before
@After
@AfterReturning
@AfterThrowing
下面哪些不支持切点中的通配符,如 `+, ..,` 和 `*`? 1. @args() 2. @within() 3. @target() 4. @annotation()
1、2、3、4
1、2、3
2、3、4
1、2、4
关于 Spring 的 PROPAGATION_REQUIRES_NEW 事务,下面说法正确的是?
内部事务回滚会导致外部事务回滚
内部事务回滚了,外部事务仍然可以提交
外部事务回滚了,内部事务也跟着回滚
内部事务回滚了,外部事务也跟着回滚
关于 Spring AOP 的描述,下列说法错误的是?
AOP将散落在系统中的“方面”代码集中实现
AOP有助于提高系统可维护性
AOP已经表现出将要替代面向对象的趋势
AOP是一种设计思想,Spring提供了一种实现
关于Spring框架模块的描述,下列说法有问题的是?
Spring Core:Core封装包是框架的最基础部分,提供IOC和依赖注入特性
AOP模块提供了AOP(拦截器)机制,并提供常用的拦截器,供用户自定义和配置
ORM模块提供了Spring自己的实现,而且支持常用的Hibernate,ibtas,jdao等框架
DAO模块Spring 提供对JDBC的支持,对JDBC进行封装,允许JDBC使用Spring资源,并能统一管理JDBC事物,并不对JDBC进行实现
在用户认证协议中,OAthu2.0应用非常广泛,OAuth2.0的哪种模式适合没有后端服务的应用?
授权码许可机制
资源拥有者凭据机制(密码模式)
客户端凭据机制
隐式许可机制
关于AOP的连接点下列说法错误的是?
连接点是一个应用执行过程中能够插入一个切面的点
连接点可以是调用方法时、抛出异常时、但不能在修改字段时
切面代码可以利用连接点插入到应用的流程中
连接点是程序执行过程中能够应用通知的所有点
JDBC 数据库事务隔离级别中,所有的事务依次逐个执行,事务之间完全不可能产生干扰的级别是?
串行化
可重复读
读已提交
读未提交
Spring Boot中,当数据库事务处理隔离级别为串行化时,spring.datasource.tomcat.default-transaction-isolation设置为?```1248```
1
2
4
8
下面哪个不是spring-boot-actuator中内置的Endpoints?
beans
httptrace
shutdown
config
下列关于 Spring 和 Spring MVC 说法错误的是?
Spring 和 SpringMVC 需要配置大量的参数
Spring 和 SpringMVC 本身不直接内嵌tomcat、netty等服务容器
Spring Boot 整合框架复杂
Spring Boot 可以内嵌tomcat、netty等服务容器
SpringBoot中`@EnableAutoConfiguration`注解的功能是?
实现配置文件的功能
打开自动配置的功能,也可以关闭某个自动配置的选项
Spring组件扫描
加载 META-INF/spring.factories 的配置信息
SpringBoot 中静态资源直接映射的优先级顺序为?
```languageMETA-INF/resources > resources > static > public```
```languageresources> META-INF/resources> static > public```
```languageMETA-INF/resources> static >resources> public```
```languageMETA-INF/resources >resources> public> static```
Spring Boot中使用拦截器,完成请求和响应后执行的方法为?
afterCompletion()
preHandle()
postHandle()
getHandle()
Spring Boot创建数据库的数据源需要添加的依赖为?
`spring-boot-starter-jdbc`
`spring-boot-starter-redis`
`spring-boot-starter-web`
`spring-boot-starter-parent`
Spring Boot中异步的方法不包括?
简单的异步调用,返回值为void
参数的异步调用,异步方法可以传入参数
异常调用返回Future
异常调用运行异常处理
@Transactional注解中,设置隔离级别的属性是?
isolation
progation
rollbackFor
timeout
下列哪种情况需要设置只读事务?
统计查询
报表查询
多条 SQL 查询
其他三项均是
给定以下代码,响应体类型是?```@GetMapping(path = "/users/{userId}", produces = "application/json;charset=UTF-8")@ResponseBodypublic User getUser(@PathVariable String userId) { // ...}```
基于传入ID的 `User` 的一个JSON响应
可显示 `User`信息的JSP网页
`User`的UTF-8文本表示
没有表示 `User`的名称空间的XML代码片段
给定以下代码:```@Repositorypublic class PersonService { public void save(Person p) { ... }}```如何在事务中执行 `save()` 方法?
用`@EnableTransactionManagement`注释方法
用 `@Rollback`注释这个方法
无需更改,`@Repository`会自动使方法具有事务性
用`@Transactional`注释该方法
下列关于Spring特性中IoC描述错误的是?
IoC是指程序之间的关系由程序代码直接操控
所谓“控制反转”,是指控制权由应用代码转到外部容器,控制权的转移
IoC将控制创建的职责搬进了框架中,并把它从应用代码脱离开来
当使用Spring的IoC容器时只需指出组件需要的对象,在运行时Spring的IoC容器会根据XML配置数据提供给它
Spring Boot中,`spring. profiles. active=development`执行的文件是?
`application.xml`
`application-development. properties`
`application- production. properties`
`application-development.xml`
执行下面一段代码,Student的实例能否创建成功并且控制台是否有打印?```@Datapublic class Student { private Integer id; private String name; private Integer cardNum;}@Configurationpublic class BeanDemo { @Bean @Conditional(TestConditional.class) public Student createBean () { System.out.println("===========this is a createBean test=========="); Student student = new Student(); return student; }}public class TestConditional implements Condition { @Override public boolean matches(ConditionContext conditionContext, AnnotatedTypeMetadata annotatedTypeMetadata) { return false; }}@SpringBootTestclass DemoApplicationTests { @Autowired Student student; @Test void contextLoads() { System.out.println(student); }}```
能创建成功,控制台有打印
不能创建成功,控制台有打印
不能创建成功,控制台无打印
能创建成功,控制台无打印
下列关于创建事务管理器并交给spring管理的方法正确的是?
```@Configurationpublic class DataSourceTransactionManager { @Bean DataSourceTransactionManager transactionManager(DataSource dataSource) { DataSourceTransactionManager dataSourceTransactionManager = new DataSourceTransactionManager(); dataSourceTransactionManager.transactionManager(dataSource); return dataSourceTransactionManager; }}```
```@Configurationpublic class DataSourceTransactionManager { @Bean DataSourceTransactionManager transactionManager() { DataSourceTransactionManager dataSourceTransactionManager = new DataSourceTransactionManager(); return dataSourceTransactionManager; }}```
```@Configurationpublic class DataSourceTransactionManager { DataSourceTransactionManager transactionManager() { DataSourceTransactionManager dataSourceTransactionManager = new DataSourceTransactionManager(); return dataSourceTransactionManager; }}```
```public class DataSourceTransactionManager { @Bean DataSourceTransactionManager transactionManager() { DataSourceTransactionManager dataSourceTransactionManager = new DataSourceTransactionManager(); return dataSourceTransactionManager; }}```
```@SpringBootApplicationpublic class DemoApplication { public static void main(String[] args) { ConfigurableApplicationContext context = SpringApplication.run(DemoApplication.class, args); MyBean bean = context.getBean(MyBean.class); System.out.println(bean); }}```如果要兼容老的Spring项目,下面配置正确的是?
在DemoApplication类上使用@ImportResource注解导入老项目的xml配置
在DemoApplication类上使用@Import注解导入老项目的xml配置
无法导入老项目的Bean
创建Component,使用Component初始化老项目Bean
关于 Spring Boot ,在开发中关于 @Autowired 的使用场景不正确的是?
@Autowired 可以用在 setter 方法生为属性赋值
@Autowired 可以用在构造函数上对 private 成员属性进行初始化
使用 @Autowired 注入要求 Bean 必须存在
@Autowired 不被推荐使用在属性注入上
在 Spring中,注解 @Scope 的代表bean的作用域,其属性值属性value取什么值使bean的生成并调用最慢?
Singleton(单例作用域)
Prototype(多例作用域)
Application(全局作用域)
Session(会话作用域)
当我们使用MyBatis时,在通过注解来配置mapper类的时候,下列哪种写法是正确的?
```@Mapperpublic interface AddressMapper { @Insert("insert into address values(#{address.id}, #{address.city}, #{address.detail})") void insertAddress(@Param("address") Address address);}```
```@Mapperpublic interface AddressMapper { @Insert("insert into address values(#{address})") void insertAddress(Address address);}```
```@Mapperpublic interface AddressMapper { @Insert("insert into address values(#{address})") void insertAddress();}```
```@Mapperpublic interface AddressMapper { @Insert("insert into address values(#{address.id}, #{address.city}, #{address.detail}, #{address.userId})") void insertAddress(@Param("abc") Address address);}```
关于Spring AOP中的Advice(增强),以下哪个说法错误?
Advice是织入到目标类连接点上的一段程序代码
Advice除了程序代码外,还拥有执行点的方位信息
Advice是AOP的核心概念之一,用于定义横切关注点
Advice是完整切面,无需与Pointcut结合使用
在一个Spring Boot应用中,你需要从application.properties文件中读取数据库连接信息。以下哪个选项有效地实现了这一需求?
在application.properties文件中直接使用`@Value`注解读取属性
使用`@ConfigurationProperties`注解创建一个配置类来映射属性
通过`@Autowired`注解直接注入Environment对象并手动读取属性
在application.properties文件中定义属性,然后使用`@Component`注解的类读取
关于Spring IoC中属性文件的加载,以下说法错误的是?
Spring可以通过`<util:properties>`标签加载类路径下的属性文件
属性文件的内容可以通过`${propertyName}`的形式在Spring配置文件中引用
`<context:property-placeholder>`标签负责加载属性文件,并扩展了Spring框架以支持数据库连接池的自动配置
使用`@Value("${propertyName}")`注解可以在Java类中注入属性文件中的值
SpringBoot中,关于`@Import`和`@ImportResource`的描述,以下错误的是?
定义配置类时,均可与`@Configuration`搭配使用
`@Import`只能修饰类
`@ImportResource`能修饰类和方法
`@Import`作用是导入额外的配置类,`@ImportResource`作用是加载XML配置文件
关于创建 Eureka Server 服务的操作,下列说法错误的是?
Eureka的服务发现包含两大组件:服务端发现组件(Eureka Server)和客户端发现组件(Eureka Client)
@EnableEurekaServer用于服务端发现
@EnableDiscoveryClient用于客户端发现
Eureka无法做到故障节点自动提出
下列关于SpringCloud Bus消息总线描述正确的是:1. 消息总线可配合SpringCloud config完成配置信息的的动态跟新2. 消息总线可用于实现微服务之间的通信3. 消息总线无法完成进程之间的数据传递
1、2、3
1、3
1、2
2、3
分布式系统与单体系统相比较,下列说法正确的是?1. 从系统性能上讲单体系统查询时间快,吞吐量小2. 从系统性能上讲分布式系统查询时间快,同时吞吐量也大3. 从系统扩展性上讲分布式系统扩张性好
1、2、3
2、3
1、2
1、3
下列关于LoadBalancer描述正确的是?1. Spring Cloud Ribbon可以自定义负载均衡策略2. 可以通过IRule接口进行扩展3. 可以在配置文件中指定NFLoadBalancerRuleClassName申明自定义的负载均衡策略类
1、2、3
1、2
2、3
1、3
zuul2相较于zuul有哪些优势:1. zuul2采用的是异步非阻塞编程,消耗线程数少2. zuul2在线程切换上下文的开销变小3. zuul2开发调试运维简单
1、2、3
1、2
1、3
2、3
Kubernetes 中 Pod 的重启策略不包括?
Always
DaemonSet
OnFailure
Never
传统项目配置有哪些局限性?1. 传统项目配置跟随源代码保存在代码库中,容易造成配置泄漏。2. 修改配置,需要重启服务才能生效。3. 无法支持动态调整:例如日志开关、功能开关。
1、2、3
1、2
1、3
2、3
下列属于 Kafka 组件的是?1. Broker2. Topic3. Producer4. Consumer
1、2、3、4
1、2、3
1、3、4
2、3、4
相比于 gRPC 框架,Thrift 的特点是?1. 需要在非常多的语言间进行数据交换2. 协议层、传输层有多种控制要求3. 需要生成较少量的代码
1、2、3
1、2
1、3
2、3
分布式和集群都是以缩短单个任务的执行时间来提升效率的。
错误
正确
单个微服务都很小,可以根据实际的访问量按需扩展。
正确
错误
下列配置不是 Eureka 服务续约的重要属性的是?
eureka.instance.lease-renewal-interval-in-seconds=30
eureka.instance.lease-expiration-duration-in-seconds=90
eureka.server.renewal-percent-threshold=0.5
以下几个选项中,关于Spring Cloud 断路器描述正确的是?
断路器是指能够关合、承载和开断正常回路条件下的电流并能在规定的时间内关合、承载和开断异常回路条件下的电流的开关装置
当某个服务发生故障时,通过断路器,会向调用方返回一个符合预期的、可处理的默认响应,而不是长时间的等待或者直接返回一个异常信息。这样就能保证服务调用方可以顺利的处理逻辑,而不是那种漫长的等待或者其他故障
其它都不对
断路器可用来分配电能,不频繁地启动异步电动机,对电源线路及电动机等实行保护,当它们发生严重的过载或者短路及欠压等故障时能自动切断电路
给出以下Spring代码段:```@Controllerpublic class RecipeController { @RequestMapping( value = "/api/quantities", method = RequestMethod.GET, params = {"recipe"} ) public String getQuantities( @RequestParam(value = "recipe") String recipe ) { //假设有效的方法代码在这里 }}```现在尝试从浏览器进行正确的访问,但是请求失败,并返回了404 HTTP状态代码。 如何通过仅修改方法解决这个问题?
在方法的返回类型之前添加`@ResponseBody`
在方法的返回类型之后添加`@RequestBody`
在方法的返回类型之前添加`@RequestBody`
在方法的返回类型之后添加`@ResponseBody`
如何在Spring MVC控制器中检索从表单上传的文件?
从处理程序方法参数`@RequestParam(“ file”)MultipartFile file`
从处理程序方法参数`@RequestParam(“ file”)File file`
通过解码文件的base64字符串表示形式
通过从表单接收的路径创建一个新的`java.io.File`
如果通过RESTful Web服务成功的发出了`GET`请求,那么服务器将与资源一起返回什么样的HTTP状态代码?
200
418
402
500
对Spring Cloud的Consul组件的说明,下列哪一项是错误的?
Consul要求强一致,所以服务注册比Eureka稍慢
Consul是Python写的程序,安装启动即可
Consul只要安装软件,就可以做为注册中心了
Consul的raft协议要求过半数的节点都写入成功,才算注册成功
以下代码属于 Spring 的哪个技术领域?```@SpringBootApplication@EnableTaskpublic class FileGenerationTaskApplication { @Autowired private DataSource dataSource; public class FileGeneratorTaskConfigurer extends DefaultTaskConfigurer { public FileGeneratorTaskConfigurer(DataSource dataSource){ super(dataSource); } } @Bean() public FileGeneratorTaskConfigurer getTaskConfigurer() { return new FileGeneratorTaskConfigurer(dataSource); } public static void main(String[] args) { SpringApplication.run(FileGenerationTaskApplication.class, args); } @Component public static class FileGeneratorTaskRunner implements ApplicationRunner { @Autowired private FulfillmentFileGenerationService service; public void run(ApplicationArguments args) throws Exception { System.out.println("FileGeneratorTaskRunner from Spring Cloud Task!"); service.fulFillmentFileGenerationTask(); } }}```
Spring MVC
Spring Data Flow
Spring Data Stream
Spring Cloud Task
下列选项中,对以下部署文件说明错误的选项是哪一个?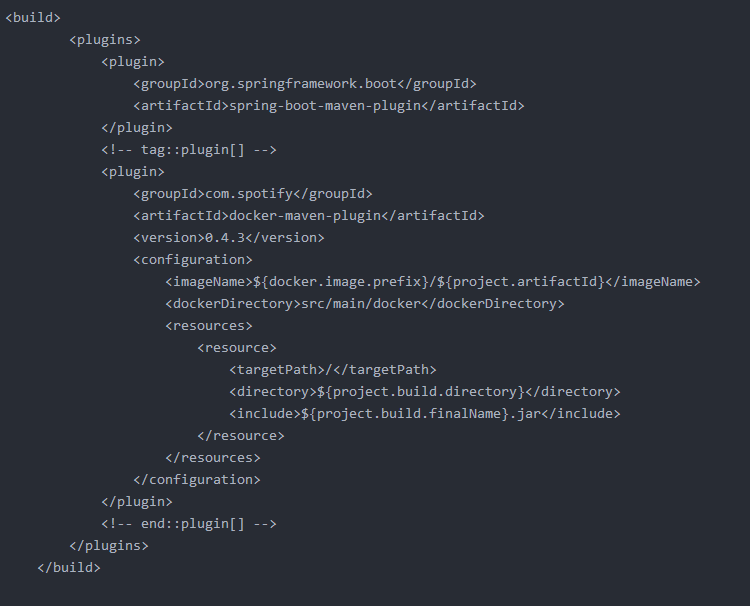
这个是Spring MVC的部署文件
imageName指定了镜像的名字
dockerDirectory指定 Dockerfile 的位置
resources是指那些需要和 Dockerfile 一起,在构建镜像时使用的文件,一般需要纳入应用 jar 包
下面哪个选项不是Spring Cloud Alibaba服务治理的内容?
微服务信息安全
服务注册
服务发现
服务健康检查
下面Spring Cloud生态圈的组件及其说明,错误的是哪个选项?
Spring Cloud Data Flow:大数据操作组件
Spring Cloud Task:提供任务调度和任务管理的功能
Ribbon:负载均衡组件
Feign:链路追踪
`Spring Cloud Bus` 的默认的配置前缀为 `spring.cloud.bus`,有关这个配置说法不正确的是?
`spring.cloud.bus.refresh.enabled` 用于开启/关闭全局刷新的 `Bus Monitor`
`spring.cloud.bus.env.enabled` 用于开启/关闭配置新增/修改的 `Endpoint`
`spring.cloud.bus.ack.enabled` 用于开启开启/关闭 `AckRemoteApplicationEvent` 事件的发送
`spring.cloud.bus.trace.enabled` 用于开启/关闭消息记录 `Trace` 的 `Listener`
独立使用`Spring Cloud Ribbon`,在没有引入`Spring Cloud Eureka`服务治理框架时,关于默认接口实现类,下面说法错误的是哪个?
`IClientConfig:Ribbon`的客户端配置,默认采用`com.netflix.cilent.config.DefaultClientConfigImpl`实现
`IRule:Ribbon`的负载均衡策略,默认采用`com.netflix.loadbalancer.ZoneAvoidanceRule`实现,该策略能够在多区域环境下选择出最佳区域的实例访问
`IPing:Ribbon`的实例检查策略,默认采用`com.netflix.loadbalancer.NoOpPing`实现
`ServerList<Server>:`服务实例清单的维护机制,默认采用`org.springframework.cloud.netflix.ribbon.ZonePreferenceServerList`实现,该策略能够优先过滤出与请求调用方处于同区域的服务实例
有关Spring Cloud,以下说法正确的是?
跨服务的事务只要能够保证每个服务内的事务逻辑正确即可
引用的依赖无需修改
不能进行配置的统一管理
即使应用所使用的编程语言不同,也能正常加入主要由Spring Cloud构建的微服务体系之中
Hystrix作用有哪些? 1、熔断 2、降级 3、隔离 4、限流
1、2、3、4
1、2、3
1、2、4
2、3、4
下列哪一个选项不是 Maven 的功能?
对项目的构建
管理项目的报告
管理项目文档
对代码的编写
假设我们要使用`application.xml`文档编写网关配置,请问下面代码下划线处应该如何补全?```........................spring: application: name: CATEWAY cloud: consul: host: localhost port: 8500 gateway: routes: ___________________________ predicates: - Path=/school/student/**```
```- id: student_route uri: http://localhost:8086 predicates: - Path=/student/**- id: school_route uri: http://localhost:8087 ```
```- id: student_route uri: http://localhost:8086 predicates: - Path=/student/**```
```- id: student_route uri: http://localhost:8086 - id: school_route uri: http://localhost:8086```
```- id: http://localhost:8086 predicates: - Path=/student/**- id: http://localhost:8087 ```
假设存在一个断言指令,请问该断言指令的判断依据是什么?```predicates:- Query=apple,phone```
请求url路径
请求路径中的查询参数
请求方式
域名
假设我们要将gateway与ribbon结合来实现切换负载均衡,要求该策略可以综合判断Server所在区域的性能 ,请问应该选择哪种ribbon负载均衡策略?
`BestAvailableRule`
`AvailabilityFilteringRule`
`WeightedResponseTimeRule`
`ZoneAvoidanceRule`
假设我们要搭建一个MyBatis的Java Web项目,下列哪个操作步骤不会出现?
导入 MyBatis 框架的 jar 包
导入映射文件 UsersMapper.xml
创建核心配置文件 sqlMapConfig.xml
创建一个 Java Web 项目
Mybatis 中,下面哪个选项中的属性表示传入参数的类型?
id
parameterType
resultType
insert
当我们在实现基于Spring Cloud的负载均衡的时候,当下游服务对于请求的处理有快有慢时,甚至有超长时处理请求时,为了防止一个实例被大量请求占用大量负载,应该选取哪种负载均衡算法?
加权随机法(Weight Random)
最小连接数法(Least Connections)
加权轮询法(Weight Round Robin)
源地址哈希法(Hash)
下面的Spring Cloud Gateway的配置中,如果我们的请求路径是`/api/v2`,当想优先匹配到`server_v2`,应该怎么配置?
```spring: cloud: gateway: default-filters: - AddRequestHeader=gateway-env, springcloud-gateway routes: - id: "server_v2" uri: "http://127.0.0.1:8002" predicates: - Path=/api/v2/** - id: "server_v1" uri: "http://127.0.0.1:8001" predicates: - Path=/api/**```
```spring: cloud: gateway: default-filters: - AddRequestHeader=gateway-env, springcloud-gateway routes: - id: "server_v1" uri: "http://127.0.0.1:8001" predicates: - Path=/api/** - id: "server_v2" uri: "http://127.0.0.1:8002" predicates: - Path=/api/v2/**```
```spring: cloud: gateway: default-filters: - AddRequestHeader=gateway-env, springcloud-gateway routes: - id: "server_v1" uri: "http://127.0.0.1:8001" predicates: - Path=/** - id: "server_v2" uri: "http://127.0.0.1:8002" predicates: - Path=/api/v2/**```
```spring: cloud: gateway: default-filters: - AddRequestHeader=gateway-env, springcloud-gateway routes: - id: "server_v2" uri: "http://127.0.0.1:8002" predicates: - Path=/api/v2/** - id: "server_v1" uri: "http://127.0.0.1:8001" predicates: - Path=/api/v2/**```
假设正在使用Jenkins和Maven构建一个Spring Cloud微服务应用,需要在Jenkinsfile文件中配置Maven的构建阶段和发布阶段。请从以下选项中选择正确的代码片段来填充/* 代码缺失 */的部分。```groovypipeline { agent any stages { stage('Checkout') { steps { git 'https://github.com/example/spring-cloud-demo.git' } } stage('Build') { steps { /* 代码缺失 */ } } stage('Deploy') { steps { /* 代码缺失 */ } } }}```
```sh 'mvn clean package -DskipTests'``````sh 'scp target/*.jar root@server:/opt/spring-cloud-demo/' // 传输文件sh 'ssh root@server "systemctl restart spring-cloud-demo.service"'```
```sh 'mvn clean install -DskipTests'``````sh 'ssh root@server "cd /opt/spring-cloud-demo/ && java -jar *.jar"'```
```sh 'mvn clean verify -DskipTests'``````sh 'ssh root@server "killall java && cd /opt/spring-cloud-demo/ && nohup java -jar *.jar &"'```
```sh 'mvn clean deploy -DskipTests'``````sh 'ssh root@server "systemctl restart spring-cloud-demo.service"'```
以下关于 Spring Boot 中的 `@LoadBalanced` 和 `@RibbonClient` 说法正确的是?
`@LoadBalanced`主要用于配置 Ribbon 客户端
被`@LoadBalanced`注释的对象,会使用RibbonLoadBalancerClient与服务进行交互
若要客户端启用负载均衡,则必须要加上`@RibbonClient`注解
可以使用`@RibbonClient`注解对客户端进行全局的负载均衡策略配置
在腾讯分布式消息队列(Tencent Distributed Message Queue, TDMQ)的技术架构中,以下关于组件交互流程的描述,哪一项是错误的?
生产者(Producer)将消息发送到TDMQ的Broker,Broker负责消息的存储和转发
消费者(Consumer)从Broker中拉取消息,Broker根据消费者的订阅情况将消息推送给相应的消费者
Broker接收到消息后,会将消息持久化存储到存储层(Storage Layer),以保证消息的可靠性
TDMQ的监控模块(Monitor)负责收集和展示系统的性能指标,但不参与消息的传输和存储流程
当 Producer 发送消息时,Broker 的职责不包括以下哪项?
验证消息权限
路由消息到对应 Partition
持久化消息到 BookKeeper
返回消息消费偏移量
TDMQ 的存储层读写分离机制对性能的主要贡献是?
减少网络带宽消耗
避免生产与消费操作相互阻塞
支持跨地域数据同步
提升消息压缩效率
当TDMQ集群管理5000+Topic时,以下哪种ZooKeeper优化方案可能适得其反?
将snapCount参数从默认100000调整为500000
为每个Topic创建独立的ZooKeeper数据路径
将tickTime从2000ms调整为1000ms
禁用zookeeper.extendedTypesEnabled扩展类型
在 TDMQ 的多地域部署架构中,跨地域的消息同步涉及到不同地域的消息代理、主题和分区。以下关于跨地域消息同步过程中组件交互流程的说法,错误的是?
源地域消息代理将需要同步的消息发送到目标地域消息代理
目标地域消息代理根据消息的主题信息,将消息路由到对应的主题和分区
同步过程中,源地域和目标地域的消息代理会进行状态同步,确保消息不丢失且不重复
源地域的主题直接将消息推送到目标地域的主题,无需经过消息代理
在 TDMQ(Tencent Distributed Message Queue)中,生产者发送消息到指定主题时,消息依次经过的核心组件及流程顺序正确的是?
生产者 → 消息代理 → 主题 → 分区 → 存储系统
生产者 → 主题 → 消息代理 → 分区 → 存储系统
生产者 → 分区 → 消息代理 → 主题 → 存储系统
生产者 → 存储系统 → 消息代理 → 主题 → 分区
当 TDMQ 消费者组中的某个消费者从分区拉取消息时,以下关于消费者、分区、消息代理以及存储系统之间交互流程的描述,错误的是?
消费者向消息代理发送拉取消息请求,指定要拉取消息的分区
消息代理接收到请求后,从存储系统中读取对应分区的消息
消息代理将读取到的消息直接返回给消费者,不进行任何处理
消费者成功接收消息后,向消息代理提交消费偏移量
TDMQ 分层架构中的生产者和消费者层与其他层的交互关系,以下说法正确的是?
生产者直接将消息发送到存储层,消费者从存储层直接读取消息
生产者将消息发送给消息代理层,消费者从消息代理层获取消息
生产者和消费者都通过中间件层(除消息代理层外)与其他层交互
生产者和消费者无需与其他层交互,自行完成消息的收发
关于 TDSQL 的架构,下面说法正确的是哪项?
TDSQL就是Mysql数据库实例
TDSQL就是腾讯的计费数据库应用架构
TDSQL架构是腾讯服务器的架构
TDSQL是腾讯的数据库集群架构
TDSQL的资源级权限指的是能够指定允许用户对哪些资源具有执行操作的能力。下面常用资源级权限的对应API名称以及配置后的控制台生效状态,说明错误的是?
恢复独享实例,ActiveDedicatedDBInstance,YES
绑定安全组,AssociateSecurityGroups,YES
查询帐号列表,DescribeAccounts,YES
实例扩容,UpgradeDBInstance,YES
创建TDSQL只读实例时,核心的条件是?
主实例启用GTID模式
主实例关闭binlog加密
只读实例与主实例硬件配置相同
主实例的存储引擎为InnoDB
某分布式 TDSQL 集群中存在一张用于记录大额交易流水的表 big_transactions,表结构如下所示,需要按照月份对 2025 年(1 月、2 月、3 月)进行 Range 分区,并将所有 3 月之后的数据统一放入一个最大分区,以便在数据库管理与性能优化方面兼顾存储与查询效率。下方代码片段中缺失了分区定义的关键部分,请选择能正确完成分区功能的代码填充到 /* 代码缺失 */ 处:```sqlCREATE TABLE big_transactions ( id BIGINT PRIMARY KEY, log_time DATETIME, details TEXT)PARTITION BY RANGE (YEAR(log_time)*100 + MONTH(log_time)) ( /* 代码缺失 */);```
```sql PARTITION p202501 VALUES LESS THAN (202501), PARTITION p202502 VALUES LESS THAN (202502), PARTITION p202503 VALUES LESS THAN (202503), PARTITION pmax VALUES LESS THAN MAXVALUE ```
```sql PARTITION p202501 VALUES LESS THAN (202501), PARTITION p202502 VALUES LESS THAN (202504), PARTITION p202503 VALUES LESS THAN (202505), PARTITION pmax VALUES LESS THAN MAXVALUE ```
```sql PARTITION p202501 VALUES LESS THAN (202502), PARTITION p202502 VALUES LESS THAN (202503), PARTITION p202503 VALUES LESS THAN (202504), PARTITION pmax VALUES LESS THAN MAXVALUE ```
```sql PARTITION p202501 VALUES LESS THAN (202502), PARTITION p202502 VALUES LESS THAN (202504), PARTITION p202503 VALUES LESS THAN (202504), PARTITION pmax VALUES LESS THAN (999999) ```
关于TDSQL(腾讯分布式数据库)的会话管理机制,下列哪个描述是准确的?
TDSQL的会话状态由客户端直接维护,连接断开后自动触发事务回滚并释放所有关联锁资源
TDSQL通过代理层(Proxy)统一管理会话的路由与状态,后端数据库节点无状态化设计,支持会话在节点故障时透明迁移
TDSQL依赖外部协调服务(如ZooKeeper)持久化会话上下文信息,节点重启后从共享存储恢复未提交事务的完整状态
TDSQL的会话与物理计算节点强绑定,事务执行期间所有查询请求必须路由至同一节点以保证ACID特性
在TDSQL中,针对高频查询的字段优化性能,开发规范建议的正确做法是?
为所有查询字段添加联合索引,避免全表扫描
使用`SELECT *`返回全部字段以减少代码复杂度
对WHERE条件中的字段强制类型转换以适配索引
仅对高频过滤字段建立索引,且避免冗余索引
在将海量数据从 MySQL 迁移至 TDSQL 分布式集群时,源库中存在多个长时间运行的未提交事务(例如,批量更新超过百万条记录),导致迁移工具频繁超时且增量同步延迟持续增加。为了高效解决这一问题,同时避免对业务造成过多压力,应如何调整迁移策略?
调大迁移工具的事务超时阈值,以容忍长事务
手动拆分源库中的未提交事务为多个小事务后重新执行
启用 TDSQL 的并行事务回放功能,并配置分片并发,以高效处理长事务
暂停增量同步,仅执行全量迁移,之后重新追日志
TSF 默认支持的负载均衡算法是?
随机轮询
加权轮询
最小连接数
一致性哈希
TSF 中回滚应用版本的正确操作是?
删除当前部署组
重新上传旧版本程序包并部署
在部署组历史记录中选择回滚
修改全局配置
TSF 容器部署组实现弹性伸缩的核心是?
CPU 使用率
日志量
调用链长度
配置版本号
在 Tencent Service Framework(TSF)中,以下哪种流量路由规则是基于请求中的 HTTP Header 信息来进行流量分发的?
权重路由
标签路由
路径路由
灰度路由
TSF中的Service Mesh(服务网格)是基于哪个开源项目实现的?
Spring Cloud
Istio
Dubbo
Kong
关闭
更多问卷
复制此问卷